
Der Einstieg in ein erstes KI-Projekt mag für viele Unternehmen eine echte Hürde darstellen. Daher habe ich bereits ein Artikel zur einfachen Implementierung von KI-Use-Cases geschrieben. In nur fünf Schritten ist man bei einem erfolgreichen ersten KI-Projekt. Das ist der eine Weg. Da dies allerdings eine Step-by-Step Guideline darstellt, ich aber die Erfahrung gemacht habe, dass die wenigsten bis keine Unternehmen so systematisch bei ihren ersten Data-Science Projekten vorgehen (wollen), da dies meist zu Beginn ein Thema der IT und/oder Entwicklung ist und nicht direkt im Feld (was ich auch dringend so empfehle!). Daher möchte ich nun für den ersten Schritt in der Produktion (nachdem man sich schon ein Grundverständnis von KI & Datenverarbeitung angeeignet hat) etwas Hilfe an die Hand geben. Dieser sollte, egal wie chaotisch das Projekt ablaufen soll, immer gleich sein: eine Status Quo Analyse.
Um also den Status Quo der eigenen AI-Readyness, wie es gerne genannt wird, herauszufinden, sollte man sich im Klaren sein, dass „KI“/„AI“ nichts anderes als Datenverarbeitung mit einer großen Priese Statistik ist. Es ist daher sehr lobenswert sich an dem eigenen Datenbestand und der eigenen Datenverfügbarkeit & Infrastruktur zu orientieren und dementsprechend hier anzufangen. Den für ein aussagekräftiges KI-Projekt brauch man vor allem eines: Daten.
Aber Stopp! Daten sind nicht gleich Daten. Beispiel: Sie haben super viele Strom- Temperatur und Drehzahlverläufe Ihrer neuen Fräsmaschine? Super! Das hilft Ihnen aber nicht weiter, wenn Sie sich an die Energieoptimierung Ihres alten Brennofens machen möchten. Wir stellen daher, um auch wirklich den richtigen Eindruck zu bekommen, was für Daten vorliegen, folgende Merkmale und Leitfragen für die Beurteilung der Datenqualität auf:
- Habe ich überhaupt die benötigten Daten? à Wenn nein entsprechende Maßnahmen treffen (an der SPS, externe Sensoren, ERP, MES etc.)
- Sind die Daten miteinander vergleichbar? Oder sind es Äpfel und Birnen à Daten müssen für Modellierung innerhalb konsistent sein, ansonsten ergibt auch der Modell-Output keinen Sinn – „Man kann nur rausholen, was man reinsteckt“
- Sind die Daten aktuell? à Es sollte immer mit neuen Daten gearbeitet werden, da nur so eine Aktualität der Aussagen gewährleistet werden kann
- Haben die Daten eine praktische Relevanz für die Aufgabe, welche ich mit Hilfe von KI lösen möchte? à Es empfiehlt sich z.B. für eine Energieoptimierung auch Daten zum Energieverbrauch zu haben etc., daher hier Domänenwissen einfließen lassen.
- Zudem sollte auf die Auflösung der Daten geschaut werden. Eine 1x/Schicht Datenpunkt nutzt sehr wenig, wenn sich der Prozess minütlich ändert…
Sind diese Grundfragen zum Datenbestand geklärt, geht es um die Datensammlung & Verarbeitung. Diese wird oft unterschätzt („Wir haben ja Daten, perfekt“), aber eine komplette Data-Science Pipeline inklusive Feedback des KI-Models schaut in etwa so aus wie ein Unendlich-Zeichen / eine liegende acht [Abb1]. Aus diesem lassen sich die sechs verschiedenen Level der AI Readyness ableiten.
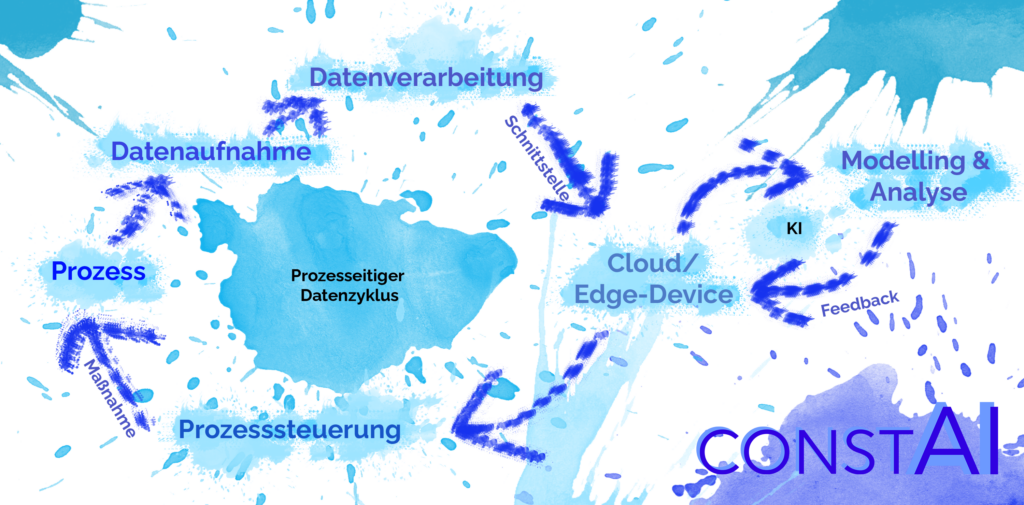
Dabei ist der linke Kreis des Unendlich-Zeichens die Prozessseite, die rechte Seite beinhaltet den Model-Input sowie Output. Um jetzt hieraus die AI-Readyness ableiten zu können, sollte man diesen Zyklus im eigenen Betrieb durchgehen. Dabei muss (und wird am Anfang) nicht der gesamte Zyklus funktionieren. Deshalb folgende Möglichkeiten, hieraus die AI-Readyness abzulesen:
Level 1: Nur Prozess steht: Es muss jetzt an Stufe zwei, der Datenaufnahme gearbeitet werden. An AI ist noch nicht zu denken. Ich kann Condition Monitoring Projekte empfehlen, um erstmal überhaupt ein Gefühl für die Daten zu bekommen. Wem das zu kompliziert ist, der kann die Daten auch erstmal nur sammeln & in Excel auswerten.
Level 2: Datenaufnahme klappt. Super! Jetzt sollte man mit den Daten nur etwas machen können. Meine Empfehlung: Erstmal verarbeiten, sammeln, und in Excel plotten. Vielleicht auch in Form von Condition Monitoring darstellen. Dann die weiteren Level durchgehen.
Level 3: Datenverarbeitung abgeschlossen, die Daten können an der SPS oder an einem beliebigen anderen Interface gesammelt werden. Schon gut. Nun wie weiter oben im Artikel beschrieben die Datenqualität checken und dann ggf. auch erst einmal in Excel plotten, anschließend ein Ziel für das Data-Science Projekt konkretisieren (z.B. OEE erhöhen, Predictive Maintenance, etc.), evtl. auch mit KI-Dienstleistern. Mit diesen an Level 4-6 arbeiten.
Level 4: Die Daten werden bereits auf der Cloud/Edge gesammelt. In dieser Stufe ist es sehr naheliegend, dass die Daten auch bereits -in welcher Form auch immer- verwendet werden. Daher ähnlich wie bei Level drei auch hier Ziel der KI/Datenanalyse konkretisieren und weitere Schritte einleiten.
Level 5: KI-System bzw. Datenanalyse bereits implementiert! Glückwunsch, ihr gehört zu ca. 5% der führenden deutschen Unternehmen in Sachen KI-Einsatz! Jetzt ist es an der Zeit, die Ergebnisse der Analyse zu nutzen. Das Feedback des Modells sollte daher mit der Prozess-/Maschinensteuerung verbunden werden und auf diese Weise ein sich selbst verbessernder und korrigierender Prozess stattfinden – oder um es in Lean auszudrücken: Jidoka. Das kann dabei in allen Arten der Analyse gehen: Gegen Maschinenausfälle & um Wartungen zu planen: Predictive Maintenance, um die Qualität zu verbessern & Ausschuss zu vermeiden: Predictive Quality oder auch um den gesamten Prozess effizienter zu machen und eine smarte Prozessteuerung zu erlangen.
Level 6: Mehr oder weniger die „Endstufe“ eines KI-Projektes und damit auch der Endgegner: Die Maschinen sammeln die Daten, diese werden in Echtzeit ausgewertet und automatisch dementsprechend der Prozess gelenkt. Der Mensch muss hier theoretisch nicht mehr eingreifen. Bis es allerdings so weit ist, sind einige Schritte zu tun. Dennoch kann auch hier theoretisch immer weiter optimiert werden: Die Modellgenauigkeit kann verbessert werden, die Responsezeiten verkürzt und die Aussagekraft um Parameter erweitert werden. Doch das ist selbstverständlich auch immer eine Wirtschaftlichkeitsbetrachtung. Ich empfehle daher, wenn man so weit ist, sich immer mit dem Bottelneck der Produktion zu beschäftigen.
Ein Zusatz zu Level 6 wären die präskriptiven Analysen, also die zuzusagen digitale Abbilung des Prozesses mit digital veränderbaren Parametern. Auf diese Weise kann man mit Parametern experimentieren, ohne die echte Produktion zu gefährden. Dafür wird der Prozess sehr genau mit allen wichtigen Einflussparameter und erklärbarer KI modelliert und auf diese Weise können eben einzelne Parameter hypothetisch verändert werden.
Das war es also soweit mit den sechs Level der AI-Readyness entworfen von constai. Falls es euch gefallen hat, ihr Hilfe braucht, oder Fragen aufkommen, so würde ich mich sehr über eure Nachricht freuen!
Liebe Grüße,
Constantin