
Bisher hat mich das Thema Datensicherheit nicht als Prio A beschäftigt, meiner bisherigen Meinung nach sind die jetzigen Sicherheitsvorgaben oft heiße Luft und unnötige Bürokratie, aber doch mindestens überzogen. Gerade in Deutschland ist das Sicherheitsbedürfnis enorm hoch und m.M. nach oft innovationshemmend. So könnten gerade Pilotprojekte mit wenig kritischen Daten oft effizienter und flexibler durchgeführt werden ohne einen 60jährigen ITler als selbsternannten “Datenschutzbeauftragten” im Team zu haben.
Aber auch ich weiß: Daten sind das neue Öl. Und bis auf die Zeit im März 2020 ist Öl ein kostbares Gut, dass keiner gerne verschenken möchte. Deshalb hat mich eben das Thema Federated Learning so hellhörig gemacht, weil es nun mal keine “alte” Technologie der Datensicherheit ist, die lieblos und auf Krampf auf ML Learning Projekte angewandt wird, sondern ein grundsätzlich innovativer Ansatz, um ML-Projekte eben ML-Projektbezogen sicherer zu machen.
Was ist Federated Machine Learning (FML) überhaupt?
Die Grundidee hinter FML ist, maschinelle Lernmodelle auf Grundlage von Datensätzen zu erstellen, die über mehrere Geräte verteilt sind. Dabei sollen Datenverluste verhindert werden, da vertrauliche Daten lokal auf einem Edge-Device trainiert werden (z.B. nachts auf dem Smartphone; auf der SPS) und so nicht auf Grund von datenschutzrechtlichen Vorgaben verworfen werden müssen, da diese nicht an einen zentralen Server geschickt werden dürfen um in ihrer Gesamtheit trainiert zu werden.
Ein Beispiel macht das deutlich: Ein Hersteller von Drehmaschinen sammelt Daten über den Drehvorgang für Predictive Quality (PQ). Dabei nutzt jeder Kunde die Drehmaschine um kundenindividuelle, oft vertrauliche Bauteile (z.B. Prototypen) zu fertigen. Diese Daten möchten viele Kunden dem Hersteller nicht für zentrale Datenmodellierung zur Verfügung stellen. Um dennoch die Gesamtheit der Drehmaschinendaten aller Kunden für PQ jedes einzelnen Kunden nutzen zu können, werden die Daten lokal trainiert und nur Parameter des trainierten Netzes wie beispielsweise Gewichte und Vernetzungen an Dritte weitergegeben/empfangen. So profitiert der Kunde von PQ ohne seine Daten hergeben zu müssen.
Der Clou im Datenschutzansatz ist hierbei, dass ein Netz alleine keine Rückschlüsse auf die Daten zulässt, mehrere Netze untereinander aber zentral zu einem „besserwissenden“ gesamten Netz zusammengefügt werden können.
Weniger industrienah wird das Beispiel für Kontodaten deutlich: Die „Cash(f)low“ Bank ist Mitglied in einem europäischen Bankennetz verschiedener Länder und hat 1000 Kundendaten über Transaktionsverläufe und Kontostände. Der belgische Ableger „Mon(d)ey“ möchte eine Software zur prädiktiven Kontoverlaufsanzeige erstellen, bei welcher von einem Kunden der erwartete Kontoverlauf des nächsten Monats prognostiziert werden soll. Die „Cash(f)low“-Bank sowie ihre anderen Schwesterbanken trainieren hierfür jeweils ein bankinternes Predictionmodell und geben nur das fertig trainierte Netz an die „Mon(d)ey“ Bank ab. Diese führt alle erhaltenen Netze zu einem größeren Modell zusammen, dass nicht nur mit den Daten der „Mon(d)ey“ Bank, sondern auch mit den Kundendaten der „Cash(f)low“ Bank sowie den weiteren Schwesterbanken trainiert wurde. Dennoch stehen der belgischen „Mon(d)ey“ Bank nur die internen Daten zur Verwendung. Die fertige Prädiktionssoftware wird wiederum allen Geldinstituten des Bankenverbunds zur Verfügung gestellt.
In Abbildung 1 habe ich versucht das beispielhaft aufzuzeigen:
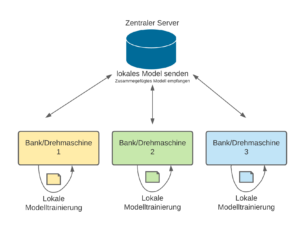
Abbildung 1: Aufbau von zentralisiertem Federated Learning, die farbigen Vierecke mit geknickter Ecke symbolisieren dabei die lokal gehaltenen Daten
Wie funktioniert das Zusammenfügen mehrerer lokal trainierter
Netze?
Die Frage, dir mir bei der Recherche stets aufkam war folgende: Wie werden die einzelnen, lokal trainierten Netze letztendlich zusammengefügt? Die Antwort darauf ist pure Mathematik. Das hatte ich zum Glück im Bachelor und darf deshalb nun ganz stolz die Antwort präsentieren:
Über Algorithmen.
Bevor ich diese aber aus den Papern übersetze und vereinfache kann ich jedem Interessenten empfehlen in die angehängten Quellen des MIT und der Cornell University in Zusammenarbeit mit Google zu schauen.
Ok, ich versuche es kurz dennoch: Der beispielsweise verwendete EM-Algorithmus startet mit einer zufälligen Auswahl der Modellparameter und verbessert den Durchlauf stets durch die neue Zuordnung von Gewichten aus anderen Modellen. Folglich wird das „Supernetz“ auf Kombination der vielen Subnetze erstellt so, dass alle Gewichte und Verbindungen bestmöglich wiedergegeben werden. Dabei ist die Einführung von neuen Layern nicht ausgeschlossen, sondern im Gegenteil ein bewährtes Mittel um mehr Tiefe und Komplexität zu erreichen
Was sind die Voraussetzungen für FML?
Um erfolgreich FML zu realisieren wird neben der entsprechenden Software auch auf besondere Hardware benötigt. Die Hardware, also das Edge-Device sollte dabei mindestens so leistungsfähig sein, dass es genug Leistung und Speicher hat um das Netz lokal zu trainieren. Für eine effiziente Weiterleitung des Netzes an den zentralen Server (beim zentralen FML), bzw. an die anderen Edge-Devices (beim dezentralisierten FML) wird eine vernünftige Bandbreite vorausgesetzt.
Zusammenfassung und Fazit
Federated Learning ist schon eine super Sache. Drei Faktoren behindern allerdings (noch) die massentaugliche Verwendung: Da wäre zum einen die komplizierte Zusammenführung mehrerer Neuronaler Netzwerke. Daneben ist die benötigte Hardware zum lokalen Training (noch) nicht der Regelfall an Maschinen (auf Handys ist eine ähnliche Form von FML schon seit längerem Gab und Gäbe). Die wenigsten SPS bzw. lokalen Steuerungseinheiten an Maschinen sind bisher mit leistungsfähiger Hardware sowie geeigneter Internetverbindung ausgestattet. Durch Themen wie IoT und Industrie 4.0 ändert sich dieser Zustand allerdings stetig. Das dritte Problem ist last but not least die mangelnde Kenntnis über FML, ein Grund, den ich nicht akzeptieren kann und daher an dieser Stelle darüber berichten musste.
Für weitere Fragen zu Federated Learning sowie Machine Learning im Allgemeinen kontaktieren Sie mich sehr gerne, ich freue mich!
Constantin Keller
consti@constai.de | 017682724836
Quellen und weiterführendes Material:
https://arxiv.org/pdf/1902.04885.pdf (Hong Kong U, Webank China, Beihang U)
https://arxiv.org/pdf/1511.03575.pdf (Google Inc, U of Edinburgh)
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/45808.pdf (Google, Cornell U, NYC)
http://www.cs.toronto.edu/~hinton/absps/hme.pdf (MIT)