
Nun bin ich seit einer guten Woche neben meinem Vollzeitmasterstudium an der TU Darmstadt zusätzlich AI Consultant Werksstudent. Das bedeutet zwar auch mehr Belastung, dafür aber auch die volle Dröhnung der Kombination von KI in Theorie & Praxis. Eine Sache kommt mir dabei allerdings etwas zu kurz: Die aktuelle Theorie und wissenschaftliche Neuerungen in der KI. Zwar bekomme ich Theorie an der Uni en masse beigebracht, dieser beschränkt sich aber auf Grundlagen a la neuronale Netze und Aktivierungsfunktionen. Grund genug uns heute einmal eine etwas weniger allgemeine Theorie anzuschauen: Die der Ausreißer bei Datenwerten. In der Standart-KI Lehre werden diese so gut wie immer im Zuge des Data-Cleaning entfernt oder im höchsten Stadium der Gefühle Stiefmütterlich behandelt und aus „Messunsicherheiten“ betrachtet. Doch was, wenn mehr hinter den Ausreißern steckt?
Unpassende Zwischenanalogie (die die Thematik aber ganz gut verdeutlicht): In der Psychologie beschäftigt man sich ja auch damit, warum Kinder von daheim ausreisen – warum also bei Daten anders vorgehen?
Warum werden Ausreißerdaten oft einfach entfernt?
Das liegt daran, dass das der leihteste Weg ist um sicherzugehen, dass Messunsicherheiten eliminiert werden. Folgendes Beispiel dazu: In einer Umfrage zur Körpergröße bewegen sich alle Messwerte zwischen 1,40 und 2.10 Meter – Daten wie 2.50m, 3m etc. sind offensichtlich Fehlmessungen, evtl. durch falsche Notation/Tippfehler entstanden. Was aber, wenn die Daten nicht so leicht greifbar sind oder Ausreiser wirklich vorkommen können? Z.B. Bei Stromverbrauchsmessungen nach Tagen? Auch hier wird oft -zu Unrecht- diese Methode der radikalen Datenlöschung angewandt. Es ist schlicht ein unkompliziertes Verfahren.
Was können Ausreißer uns sagen?
Manche nicht fehlerhaft gemessene Ausreißer können beispielsweise auf ein drohendes Ereignis deuten. Dies ist im Wesentlichen eine der Methoden, die Predictive Maintenance/Quality sowie anderen Datenbasierten Prognosen zum Einsatz kommt. Die zentrale Fragestellung lautet also: Was ist hier (=zum Messzeitpunkt) passiert? Die Antwort hierauf ist selbstverständlich nicht allgemein, sondern fallspezifisch zu beantworten. Methoden wie das heranziehen parallel aufgenommener Datensätze sowie die Befragung von Mitarbeitern zu bestimmten Ereignissen erweisen sich aber als die beiden Key-Analyseinstrumente. Gerade hier zeigt sich die Wichtigkeit von Data Understanding: Der Data-Scientist muss ganz genau wissen, wie seine Daten entstehen und den Zusammenhang mit der Wirklichkeit im Blick behalten. Ich stelle daher folgenschwere These auf:
„Lieber ein Ingenieur mit einigen Data-Science Skills als ein Informatik-Theoretiker als Data Scientist“
Deshalb liebe Ingenieurskommilitonen: Schaut zu, dass ihr euch Data-Science Werkzeuge aneignet oder eure Data-Scientisten Kollegen genau über die einzelnen Sachverhalte aufklärt! Danke. Daten sind nämlich ursprünglich keine reinen Zahlen, sondern spiegeln vergangene Ereignisse wider.
Ausreißer müssen sich nicht auf eine Dimension beschränken!
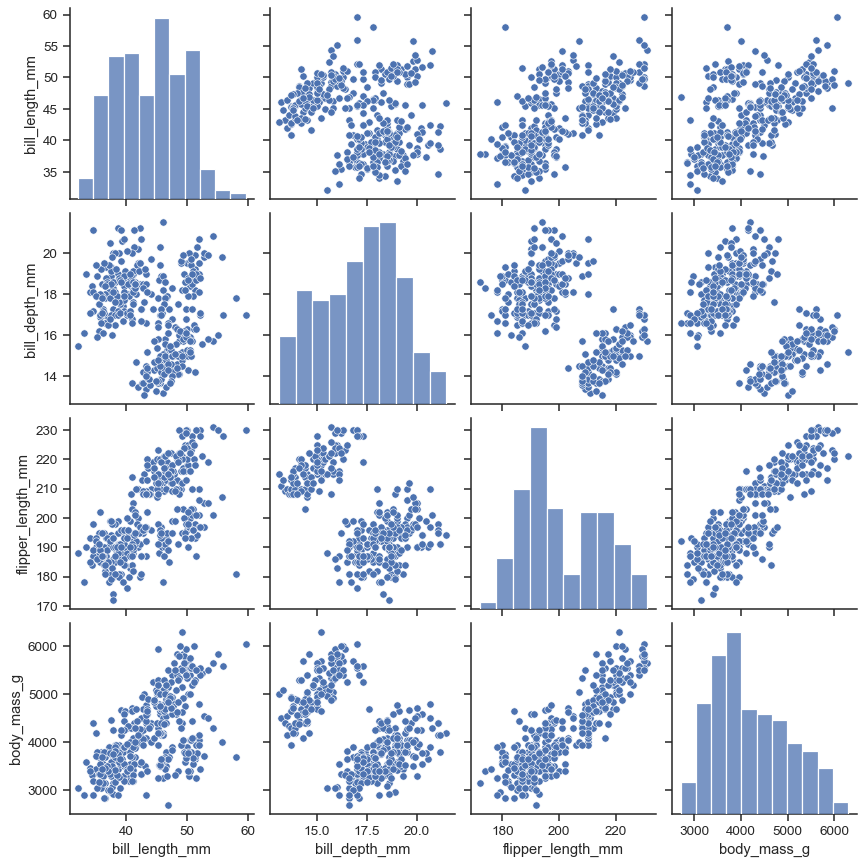
Ich möchte an dieser Stelle zusätzlich darauf hinweisen, dass bei der Arbeit mit mehreren Datensätzen diese niemals getrennt voneinander betrachtet werden dürfen. Das kann gerade bei der Missing-Value und Outlier Behandlung schwerwiegende Folgen (Informationsverlust, Informationsverfälschung etc.) haben, wie wir im späteren Beispiel sehen werden. Hierfür gilt die Regel: bevor Datenpunkte auf Grund von „blindem Aktionismus“ entfernt/bearbeitet werden, immer erst einen Überblick über den gesamten Datensatz bekommen und verschiedene Daten in Korrelation zu sehen. Dafür kann ich den Seaborn Pairplot (sns.pairplot) besonders empfehlen. In diesem werden alle Daten paarweise abgebildet:
Kannst du uns ein Beispiel für wichtige Ausreißer nennen?
Gerne! Stellt euch ein Montageroboter bei einem großen Batteriehersteller vor. Er montiert den ganzen Tag Batteriezellen für Elektroautos indem er die Zellpakete mit Polen und Gehäuse verbindet. Es werden dafür unter anderem die Kraft gemessen, mit welcher der Roboter die Zellpakete in die Gehäuse steckt. Die Daten schauen dabei so aus:
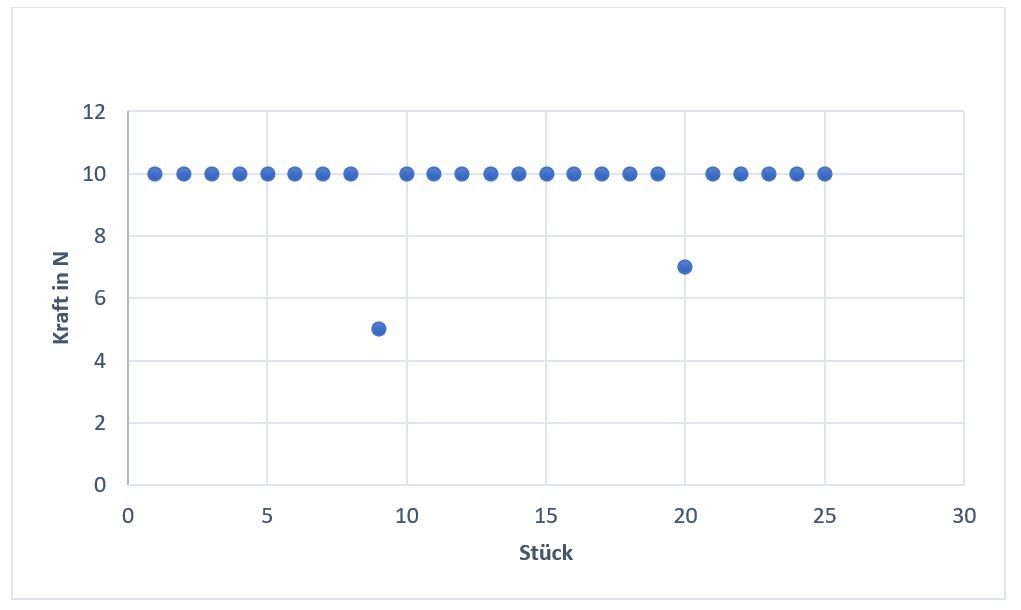
Nun fällt sofort auf, dass bei Stück 9 & 20 die Kraft vom offensichtlichen Soll (10N) abweicht. Ein schlechter Data Scientist würde nun auf Messabweichungen schließen und die Daten auf 10 runterkorrigieren oder löschen. Was aber, wenn die Kraft bei 9 & 20 so viel geringer war, weil an den Zellen eine Metallplatte zu klein war? Das würde vermutlich in keinem Qualitätscheck auffallen, könnte aber bei einem Akkucrash oder bei viel Benutzung einen Brand verursachen.
Das wäre jetzt selbstverständlich ein Worst Case Szenario, aber wenn man sich die damit verbundenen Gewichte der Batteriezellen anschaut, sieht man einen Zusammenhang:
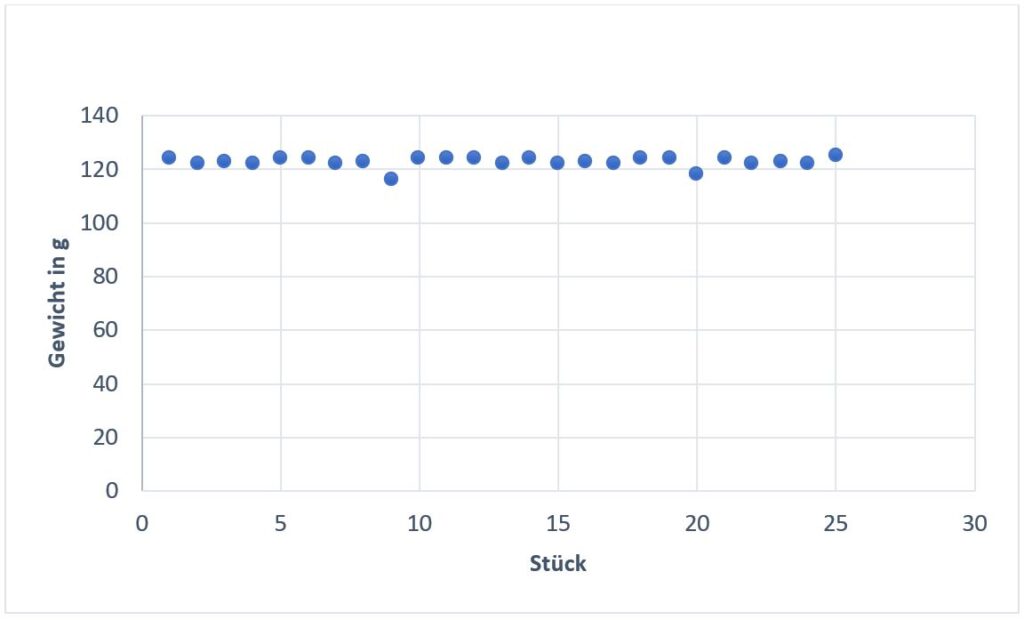
Nun wird ganz klar deutlich, dass es sich nicht bloß um Messfehler handelt. Bei Batteriezelle 9 & 20 ist tatsächlich ein geringeres Gewicht festzustellen als bei den anderen Bauteilen. Für sich betrachtet würde das Gewicht-Stück Diagramm allerdings auch darauf deuten, dass bei 9 & 20 ein Messfehler passiert ist. Es zeigt sich einmal mehr, dass es sich lohnt den gesamten Datensatz im Blick zu behalten.
Das soll es für diese Lektion gewesen sein. Ich bedanke mich wie immer fürs Lesen.
Liebe Grüße,
Consti
PS: Für Anregung und Updates folgt gerne der constai.de Instaseite!